从单体到智能 图解分布式架构演进与人工智能应用的软件开发
在当今以数据驱动和智能化为核心的技术浪潮中,分布式架构已成为构建大规模、高可用性系统的基石,而人工智能(AI)的深度融合,正引领着软件开发进入一个全新的范式。本文将通过图解与解析,梳理分布式架构的发展脉络,并探讨其在人工智能应用软件开发中的关键作用与最新实践。
一、 分布式架构的演进图谱
分布式架构的演进并非一蹴而就,其发展历程清晰地反映了业务复杂度与数据规模的爆炸式增长。
第一阶段:单体架构 (Monolithic Architecture)
- 图示核心:一个单一的、庞大的代码库,包含所有功能模块(如用户界面、业务逻辑、数据访问层),通常部署在一个进程中。
- 特点:开发简单,初期部署快。但随着功能增加,代码变得臃肿,维护困难,牵一发而动全身,扩展性差(只能垂直扩展)。
第二阶段:垂直分层架构 (Layered Architecture)
- 图示核心:在单体内部,按关注点分离为表现层、业务逻辑层、数据访问层等。这是架构清晰化的第一步,但本质上仍是单体。
第三阶段:面向服务架构 (SOA, Service-Oriented Architecture)
- 图示核心:系统被拆分为一组松耦合的“服务”,通过企业服务总线(ESB)进行通信和集成。服务通常较粗粒度(如“用户服务”、“订单服务”)。
- 演进意义:实现了服务的复用和业务的灵活组合,但ESB可能成为性能和单点故障的瓶颈。
第四阶段:微服务架构 (Microservices Architecture)
- 图示核心:SOA思想的精细化与实践化。系统被拆分为一组更小、独立部署、围绕业务能力构建的细粒度服务。每个服务拥有独立的数据存储,通过轻量级协议(如HTTP/REST, gRPC)直接通信。
- 关键赋能:独立开发与部署、技术异构性(不同服务可用不同语言/框架)、弹性扩展。但带来了服务治理、分布式事务、监控等复杂性。
第五阶段:云原生与服务网格 (Cloud-Native & Service Mesh)
- 图示核心:微服务部署在容器(如Docker)中,由编排系统(如Kubernetes)统一管理。服务间的通信、安全、可观测性等“非业务功能”被下沉到服务网格(如Istio)这一基础设施层。
- 演进意义:将开发人员从复杂的分布式通信治理中解放出来,更专注于业务逻辑。实现了架构的彻底解耦与运维的自动化。
第六阶段:无服务器与事件驱动 (Serverless & Event-Driven)
- 图示核心:函数即服务(FaaS)成为计算单元,由云平台根据事件触发(如HTTP请求、消息队列事件)动态调度运行,按实际使用计费。后端服务(BaaS)提供托管服务。
- 演进方向:进一步抽象基础设施,追求极致的弹性与成本效率,适用于异步、事件驱动的场景。
二、 人工智能应用软件开发的分布式架构挑战与融合
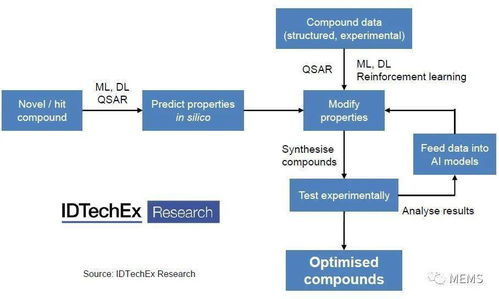
人工智能应用,特别是涉及大规模模型训练、实时推理、流式数据处理的应用,对分布式架构提出了独特需求并与之深度融合。
1. 数据处理与训练阶段:计算密集型分布式
挑战:海量训练数据、巨大的模型参数(如大语言模型)。
架构融合:
* 数据并行:将训练数据分片,分布在多个计算节点(GPU/TPU集群)上,同步训练同一模型。
- 模型并行:将巨型模型本身的不同层或部分拆分到不同设备上。
- 流水线并行:将模型按层分段,像工厂流水线一样在不同设备上并行处理不同批次的样本。
- 图解示例:一个由参数服务器(PS)或All-Reduce通信模式连接的庞大计算集群,协同完成分布式训练任务。
2. 模型部署与推理阶段:高并发、低延迟服务化
挑战:将训练好的模型以API形式提供稳定、高效、可扩展的在线预测服务。
架构融合:
* 模型即服务 (MaaS):将模型封装为独立的微服务。利用Kubernetes进行弹性伸缩,根据请求量自动增减模型服务实例。
- 服务网格赋能:通过服务网格管理模型服务间的流量路由、A/B测试(用于模型版本灰度发布)、熔断和限流,保障推理服务的稳定性。
- 边缘计算:对于实时性要求极高的场景(如自动驾驶),将轻量级模型部署在边缘设备,形成云-边-端协同的分布式推理架构。
3. 特征工程与数据流:实时事件驱动
挑战:AI应用往往需要处理实时数据流,进行特征计算并触发模型推理(如推荐系统、欺诈检测)。
架构融合:采用事件驱动架构。使用消息队列(如Kafka, Pulsar)作为中枢,连接数据源、流处理引擎(如Flink, Spark Streaming)进行实时特征计算,并事件触发推理服务。这本质上是分布式的、松耦合的流水线。
4. 机器学习工作流编排:分布式管道
挑战:AI开发包含数据收集、清洗、训练、评估、部署等多个步骤,需要自动化、可复现的流水线。
架构融合:采用如Kubeflow, MLflow等MLOps平台。这些平台基于Kubernetes,将每个步骤(如数据预处理、模型训练)封装为可独立运行、可伸缩的容器化任务,并通过DAG(有向无环图)进行编排,构成一个分布式的工作流系统。
三、 未来展望:智能化与分布式的共生演进
分布式架构与人工智能正在形成正向循环:
- AI for Infrastructure:利用AI来优化分布式系统本身,如智能流量调度、故障预测、资源自动扩缩容,实现“自动驾驶”的运维。
- Infrastructure for AI:更强大、更易用的云原生分布式基础设施(如专为AI设计的高速互联、异构计算调度),持续降低大规模AI应用开发与部署的门槛。
结论:分布式架构的演进,从解耦单体到云原生智能化,其核心驱动力始终是应对规模与复杂性的挑战。而在人工智能时代,分布式架构不仅是承载AI应用的“躯体”,其自身也正在吸收AI技术变得更具“智慧”。对于“技术头条”的读者和人工智能应用软件的开发者而言,深刻理解这一共生演进关系,掌握将分布式系统设计模式与AI工作流相结合的技能,是构建下一代智能、弹性、可靠软件系统的关键所在。
如若转载,请注明出处:http://www.lkdshoi.com/product/20.html
更新时间:2026-06-19 11:20:19